Hey there, I’m Casey Jones.
Let me ask you something…
Is your marketing delivering the ROI it should? Are you confident you’re capturing every opportunity in your market?
Or are you watching competitors gain ground while your growth plateaus?
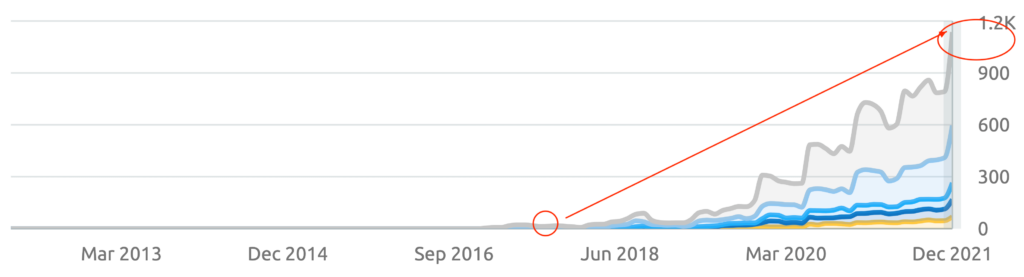
Markets are more volatile than ever.
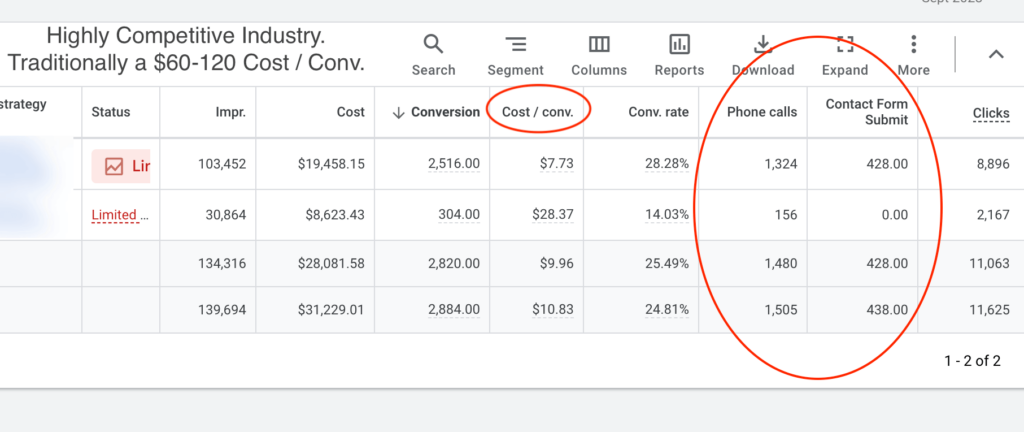
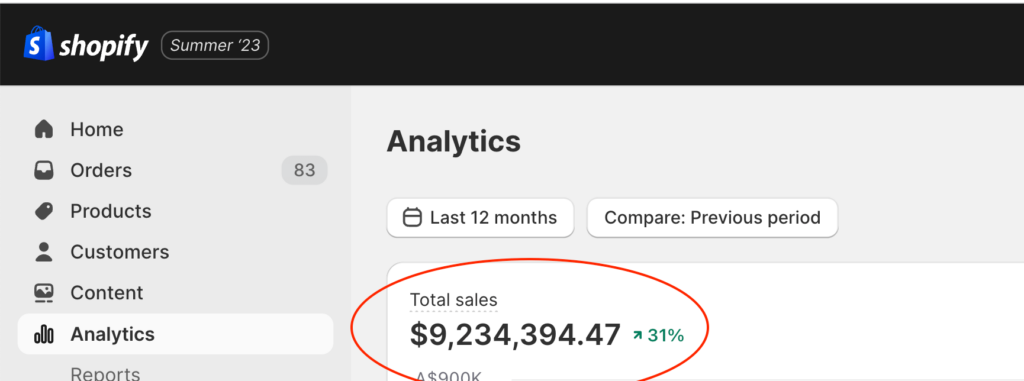
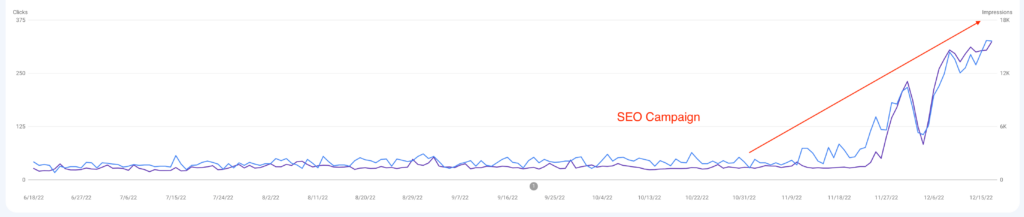
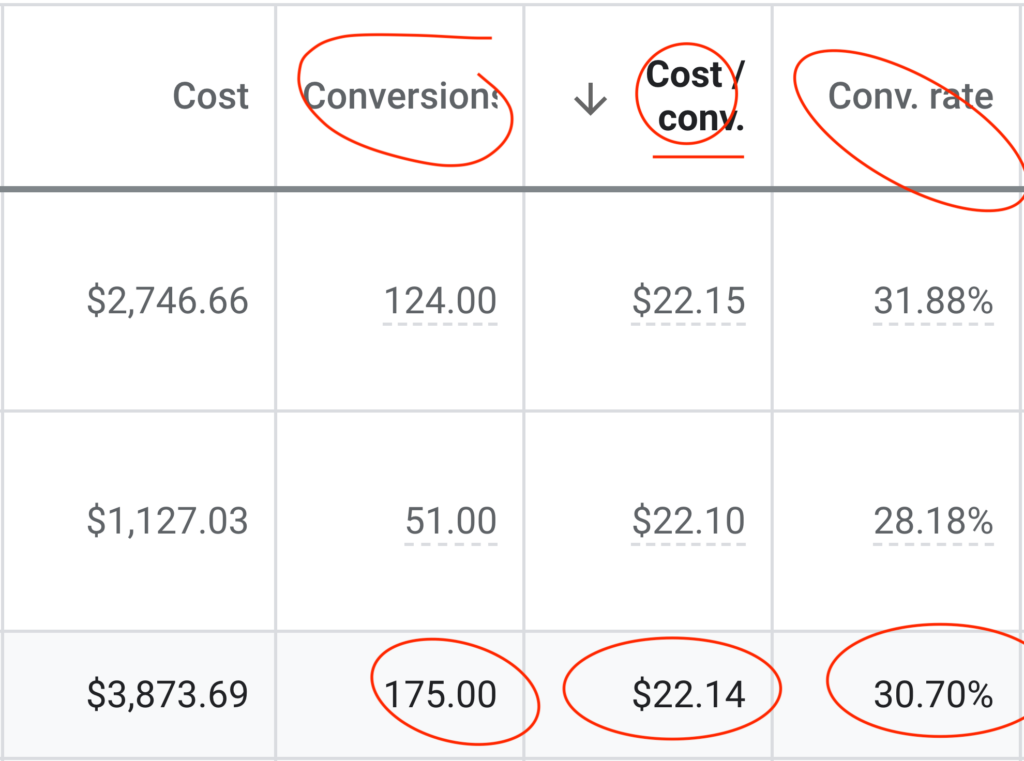
Customer acquisition costs are soaring. Digital landscapes shift weekly. And your marketing needs to work harder than ever before.
The fragmented digital landscape. Rising ad costs eating into profitability. Complex customer journeys that need constant optimisation.
And marketing teams stretched too thin.
If you’re nodding along, you’re not alone.
Whether you’re leading a growing business ready to scale, an established company seeking better returns, or an enterprise expanding market share, you’re likely facing similar challenges.
Your current agency lacks strategic depth.
(or they just seem to slide into the bushes when you try and call them)
Your in-house team needs specialist support.
Or your marketing results just aren’t matching your business ambitions.
The truth? You’ve likely tried different approaches.
Maybe multiple agencies. Perhaps expanded your internal team. Tested various channels.
Invested in the latest tools.
Punched into chatgpt “give me marketing ideas to grow my business”…
But something’s still missing.
You’re here because you need more than just another agency. You need a partner who understands your market position, knows how to protect and grow market share, and can align marketing with your business objectives.
That’s exactly why I do things differently at CJ&CO.
My team of 15+ experts brings both strategic insight and tactical excellence.
For some clients, we’re their entire marketing department. For others, I’m a strategic partner supporting internal teams. And for enterprises, we’re a specialist team filling crucial capability gaps.
What makes us different?
We start by understanding your business context. Your market position. Your competitive advantages.
Your operational constraints. And most importantly – your growth objectives.
This isn’t about quick fixes or short-term metrics. It’s about sustainable growth and real business impact.
If you’re seeking a more strategic marketing approach, looking to scale proven channels, needing specialist digital expertise, or wanting better returns from your marketing investment – let’s talk.
Oh and if you’re looking for a team that actually gives a sh*t! That’s us!
The process starts with a super-candid conversation about your business.
Look, I have no idea if I can help. We haven’t even met yet. And while you’re reading about me, I have no idea about you.
That’s why you should scroll down, find one of those big shiny buttons that has a phone number or contact link and reach out.
I’ll tell you straight whether we can or cannot help.
No pitches.
No pressure.
Just straight talk about what’s possible.
Right now, you have two choices: Keep things as they are, or explore what’s possible with a different approach.
The next step is yours.
























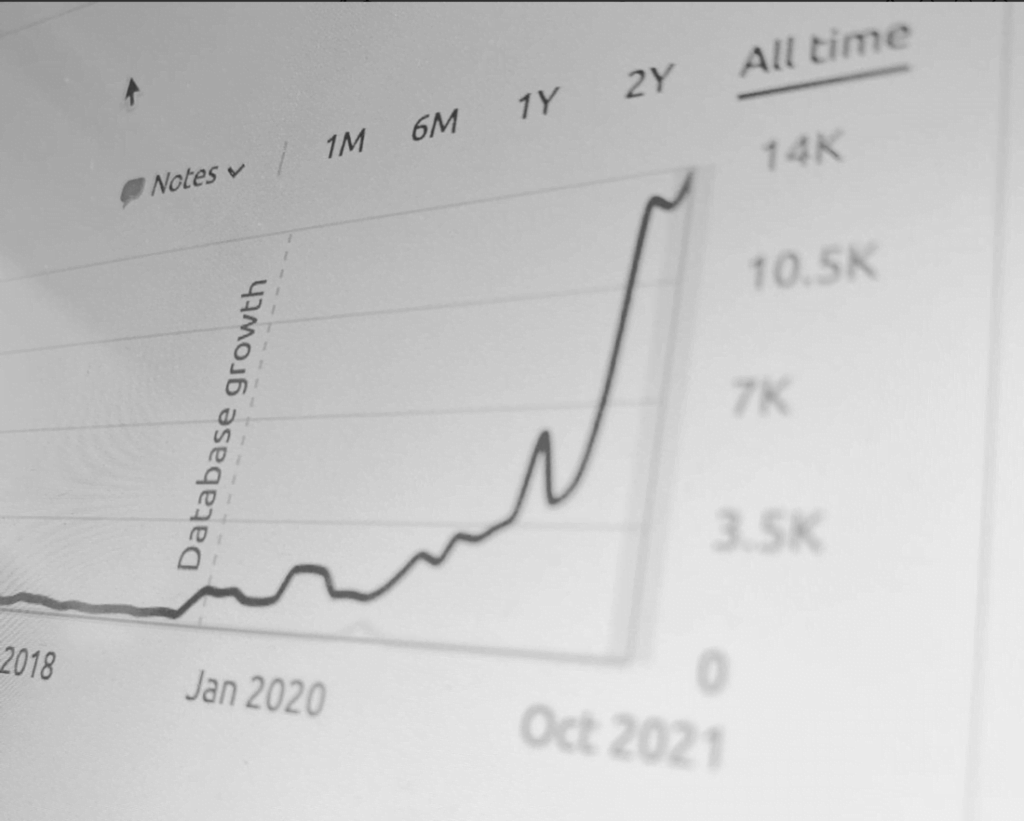

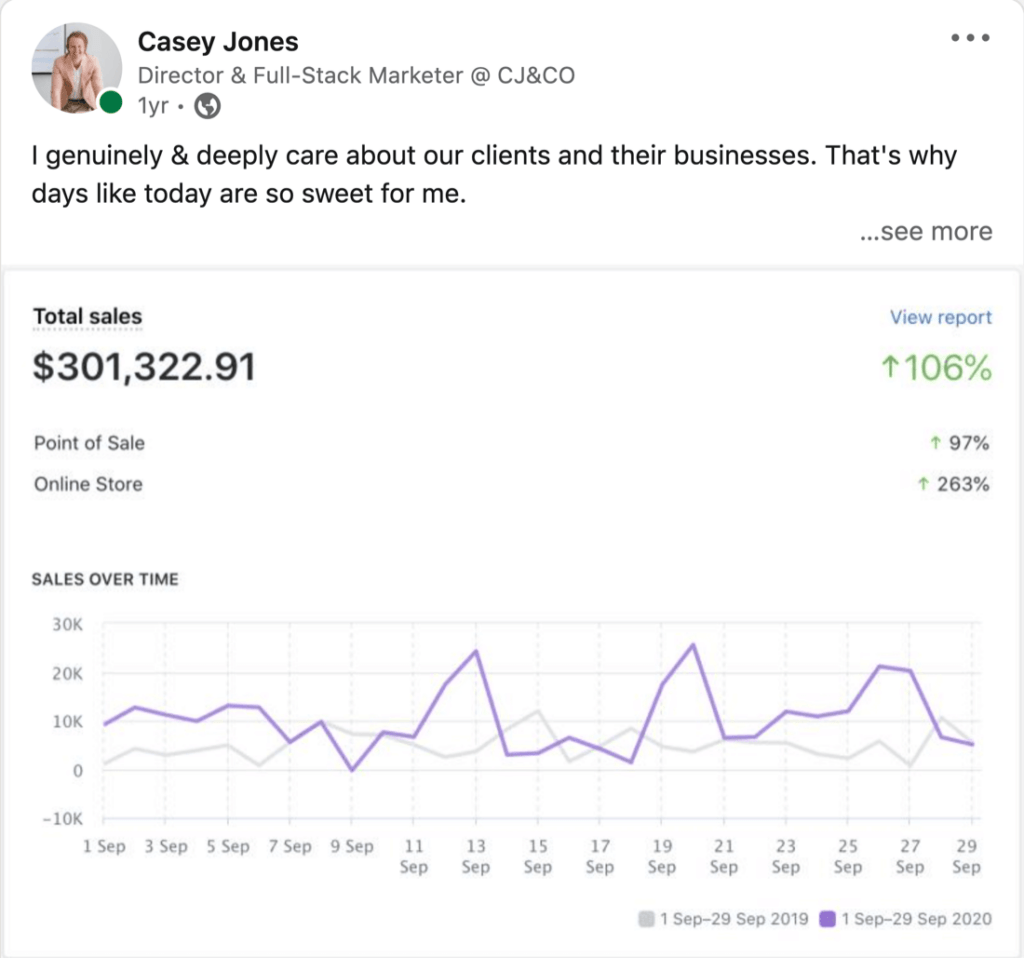

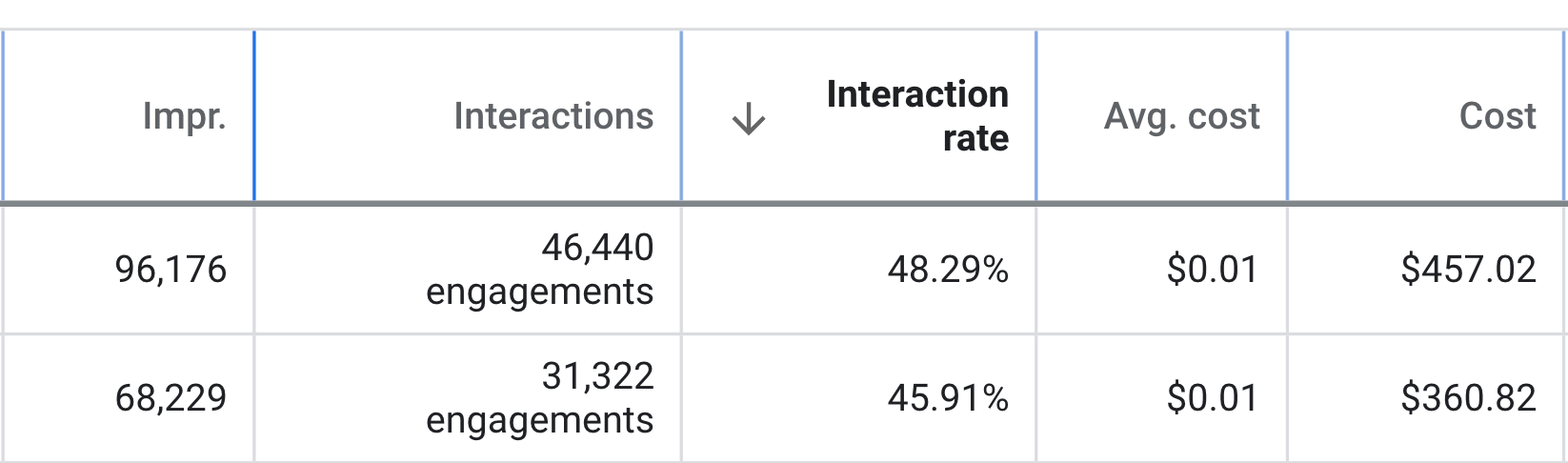

























Amazing team with an amazing vision. Executed the website I wanted masterfully! Would definitely recommend them to all small business owners looking to make a statement onlineRead moreRead less
CJCO has truly exceeded my expectations. From the very first interaction, it was clear that their commitment to excellence shines through in every aspect of their work. They handle every detail with care, addressing any concerns or inquiries I had with remarkable responsiveness and genuine accommodation. The end result was nothing short of fantastic, leaving me thoroughly satisfied. I would like to extend my heartfelt gratitude to Casey, Mits, and the entire team for their outstanding efforts. Hats off to all of you!Read moreRead less
As an experienced health professional I am a hard sceptic when is comes to quality services. I was pleasantly surprised when Casey and the ever brilliant Mits on his team over delivered on my project with an A+ website design having actively listened to every point I was seeking, providing an efficient, professional and helpful service. This is an A+ grade gem of a business and is highly recommended.Read moreRead less
Casey, Mits & Team, HATS OFF to the best web developers out there! I could not have asked for a better teamteam to work with, you guys are dedicated to your work and are amazing with your time, consistency effort and love that you pour into what you guys do best! So responsive with communication So Kind and bubbly nature You will know you are in the right hands as soon as you book you appointment with Casey! I am so grateful and thankful for meeting and working with such a great team! THESE GUYS ARE YOUR NUMBER ONE TEAM! THEY ARE GAME ON DONT THINK TWICE! My experience with CJ&Co is far more than 5 Stars DEFINATLYRead moreRead less
Casey helped me in designing a logo for my company. He exceeded my expectations. There was a detailed explanation on each part of the design. They are 100% worth the investment. Casey is easy to talk to and very reliable. He told me it can take up to 10 business days for the logo to be made but it took only 2 days! I'm very impressed. I would love for their team to do my website too. Thank you, Casey and the whole team. I'm very grateful for your help.Read moreRead less
Friendly, easy to work with and high quality production of the website. Would recommend.
Excellent company to deal with and their web design is incredible. Would use them again and again.
Really happy with the website made by the team at CJ&CO! They met our requirements and actioned any feedback promptly and accurately.ely. Casey was very helpful and informative throughout the process. The quality of the website and design is flawless and would highly reccomend CJ&CO for anyone considering website development.Read moreRead less
I am so grateful to Casey and the crew at CJ&CO. I came to them with major issues and Casey helped med me to stay positive. This company is 100% the easiest to deal with and their work is outstanding. I would recommend anyone that comes across this company to don't scroll past without making a call! A++++Read moreRead less
Casey has been an absolute standout! His personalised approach has been nothing short of incredible. We have had amazing results from the get-go and I'd highly recommend Casey and his team to anyone looking for assistance with their digital marketing!Read moreRead less
We have worked with Casey on a number of website projects and are super impressed with his promptness, communication, professionalism, and knowledge of the full suite of digital marketing. Thank you Casey! You and your team are second to none! 🙏Read moreRead less
Casey was so empathetic and patient in listening to my ideas. He asked all the right questions and got me thinking on aspects I hadn't considered. He goes above and beyond. You can trust on him to do the best for your business in the long run. If you want a marketing agency that is truly experienced and REALLY wants to help you grow your business, pick CJ&CO, you won't regret it.Read moreRead less
I engaged CJ&CO to take on marketing my NDIS business recently. Casey and his team have been incredibly positive in their approachoach and patient with my endless questions. I'm looking forward to working with CJ&CO in the future!Read moreRead less
To the insightful marketing behemoth that Casey brings to our whole world of getting in the customers focus zone, once again your insightful strategies always go above and beyond the normality of blanket marketing and get us some enviable results from our competitors and partners alike. Keep up the efforts mate. You are our connection to the customer.Read moreRead less
Up until working with Casey, we had only had poor to mediocre experiences outsourcing work to agencies. Casey & the team atm at CJ&CO are the exception to the rule. Communication was beyond great, his understanding of our vision was phenomenal, and instead of needing babysitting like the other agencies we worked with, he was not only completely dependable but also gave us sound suggestions on how to get better results, at the risk of us not needing him for the initial job we requested (absolute gem). This has truly been the first time we worked with someone outside of our business that quickly grasped our vision, and that I could completely forget about and would still deliver above expectations. I honestly can't wait to work in many more projects together!Read moreRead less
Casey is professional, enthusiastic and knowledgeable. He was quick to identify where we could improve our business, and made a huge impact to our brand. Could not recommend these guys enough!Read moreRead less
Extremely happy with Casey and his team. If you're looking for a highly experienced, knowledgeable and ideas-driven marketing agency, look no further. Not only is Casey exceptionally skilled at creating highly effective marketing strategies and delivering real results, he's a pleasure to work with and a great communicator. He's helped transform our business from a fairly humble start-up to a fast growing and highly regarded service provider in our industry. He knows his stuff and we couldn't be happier. Five Stars.Read moreRead less
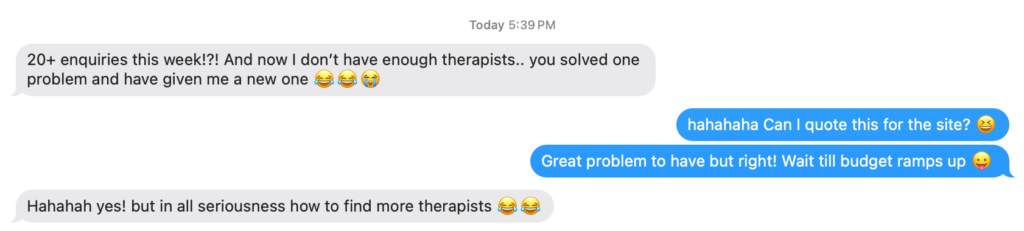
The enquiries just keep coming and the business is now unrecognisable. But, what we like most about Casey, is he's a great communicator, really easy to work with and responsive to our needs.Read moreRead less
FIT Merchandising have been using the CJ & Co for about 7 years and love the professionalism , timely turnaround on projectsects , cost structure and all round quality of service we receive form them. Casey is highly skilled in all things digital marketing our brand would be lost with out his and his team.Read moreRead less
CJ&CO has helped me to steadily gain clients so much that I'm now looking at taking on additional staff to meet the the demand.Read moreRead less
I'd highly recommend Casey to business owners who are looking to take that plunge to market their business online.
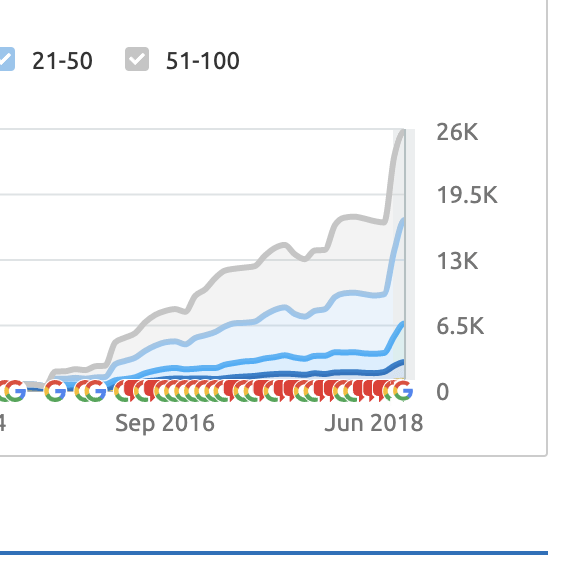
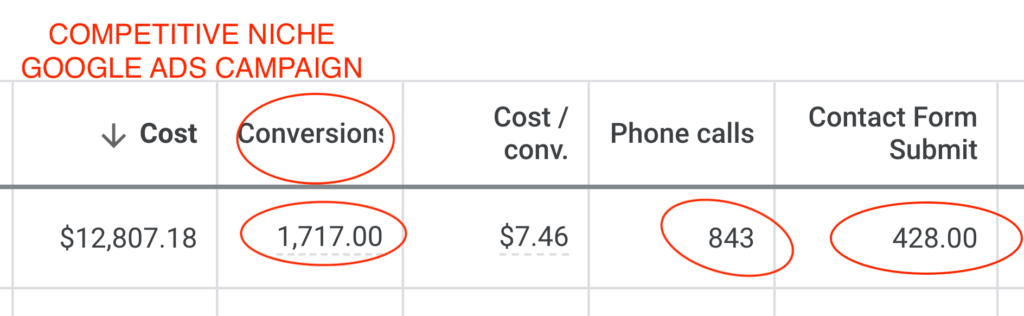
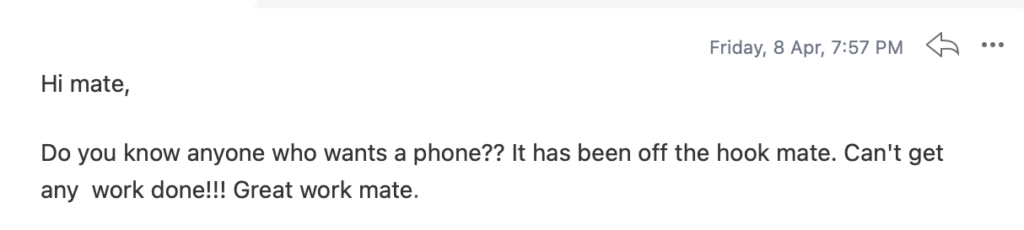
Within a very short amount of time, the leads coming in the door were AMAZING!
My business is thriving. They developed a new easy to use website for me whilst also managing my Google AdWords account.
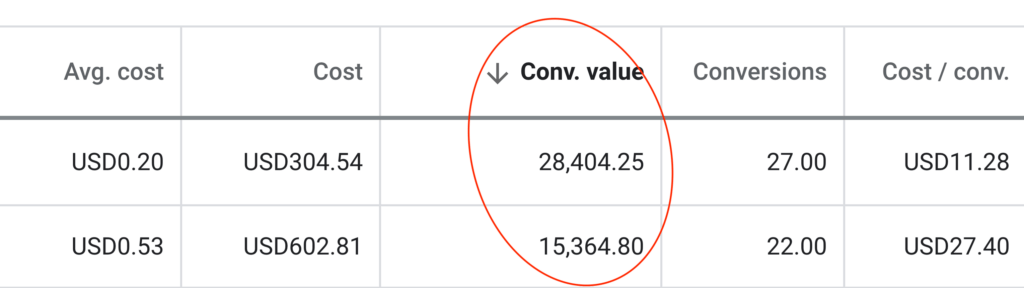
I used to enjoy doing my own marketing. Landing leads and cinching clients is a real endorphin rush. However, it was very hit or miss. One day, something changed and after almost $300 in Facebook ad spend, I didn’t land a single lead. I couldn’t figure it out and got referred to CJ&CO from a fellow OT. Within a month, with Casey's short-term strategy, the leads were rolling in!Read moreRead less