Hey there, it’s Casey Jones here.
This could be the most important thing you read all year.
Ever felt like you’re running full-tilt on a treadmill, sweating bullets, but not making a dent in your business goals?
Struggling with leads and sales as weak as a kitten?
You’re not the only one.
Here’s the unvarnished truth: the business world is a relentless, cutthroat jungle where most are just prey waiting to be devoured.
The numbers?
Bleak as hell.
One-third of businesses bite the dust in a year, half are pushing up daisies by year two, and a staggering 66% vanish into oblivion by year five.
But wipe those tears away and buckle up, because CJ&CO is here to pull you out of the abyss.
As a full-service creative and marketing powerhouse, CJ&CO’s mission is to elevate businesses like yours from the quagmire and unleash a torrent of revenue and profit.
Armed with a team of 15+ industry ninjas, we’ve got the skills and wisdom to deliver the goods, and we’re primed to concoct a custom marketing plan that hits the bullseye.
We know that every business is a one-of-a-kind masterpiece, so we’re all about crafting bespoke strategies for each of our clients, tailored as perfectly as a Savile Row suit.
Our game plan?
Listen to your dreams, confront your challenges like a matador, and team up to forge a plan that caters to your needs like a five-star chef.
And believe me, we’re not just spinning a yarn here.
Our track record is as solid as the Great Wall of China, with a glittering collection of awards and a parade of ecstatic clients as evidence.
If you’re ready to rocket your business to stratospheric heights, it’s time to get in touch with us.
We’re pumped to share our expertise and help you obliterate the competition.
From sculpting the ultimate marketing plan to launching it and measuring success, we’re your trusty sherpa guiding you up the Everest of business growth.
We’re all about open communication and being there when you need us, like a faithful golden retriever – no disappearing acts, we swear.
You’ve poured blood, sweat, and tears into building your business, but without the right marketing strategy, you’ll be forever stuck in the minor leagues.
With our expert guidance, you can finally witness the jaw-dropping results you’ve earned and deserve.
Don’t let this golden opportunity slip through your fingers like sand on a beach.
Reach out to us today, and let’s catapult your business to dizzying new heights!
Click that link, and together, we’ll embark on an epic adventure to transform your business into a force to be reckoned with.

















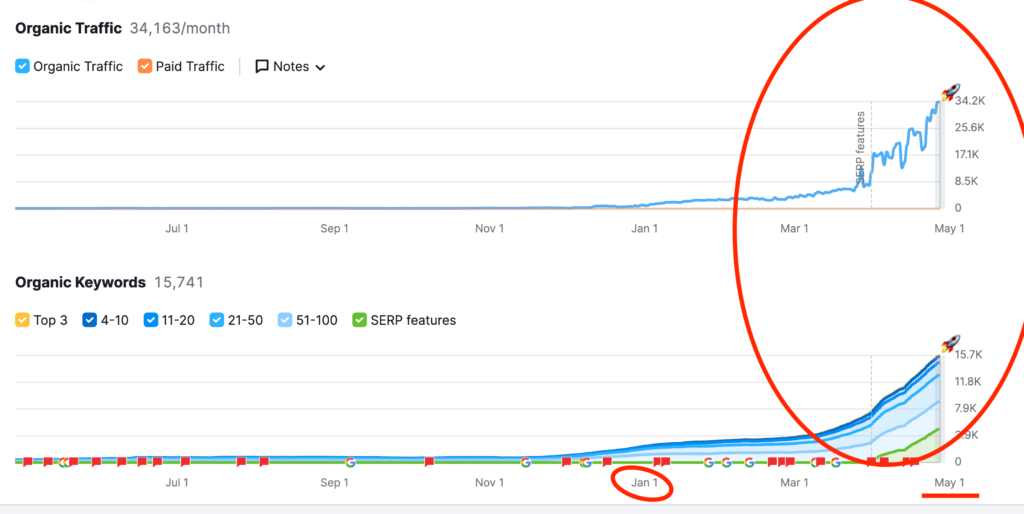
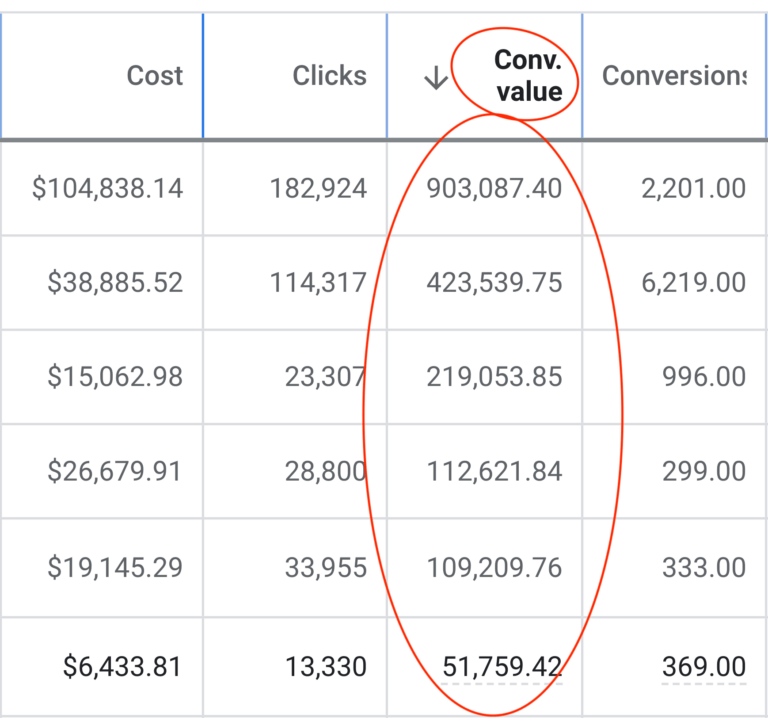
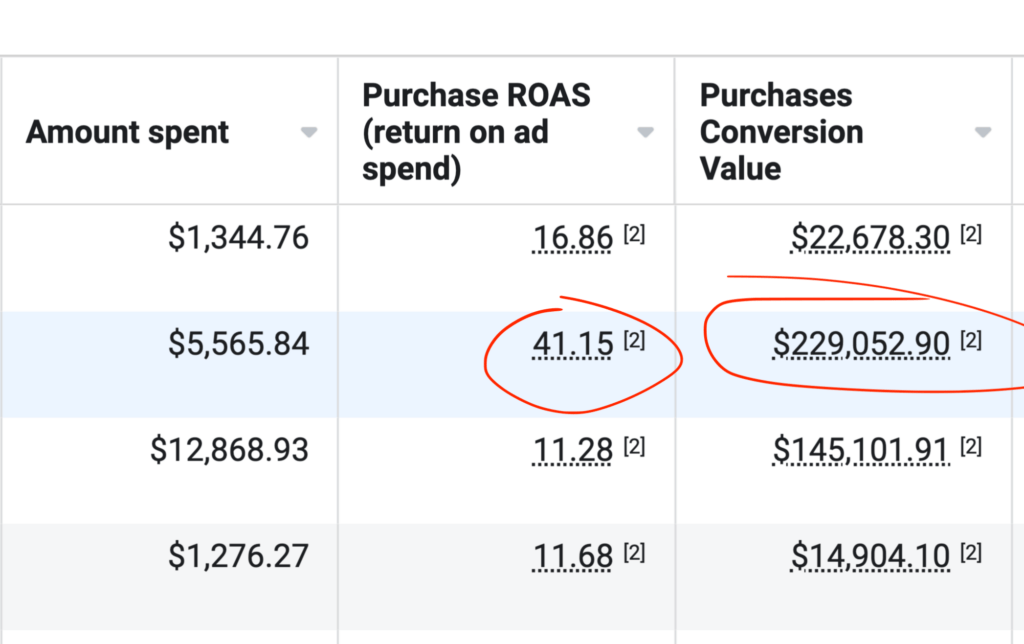
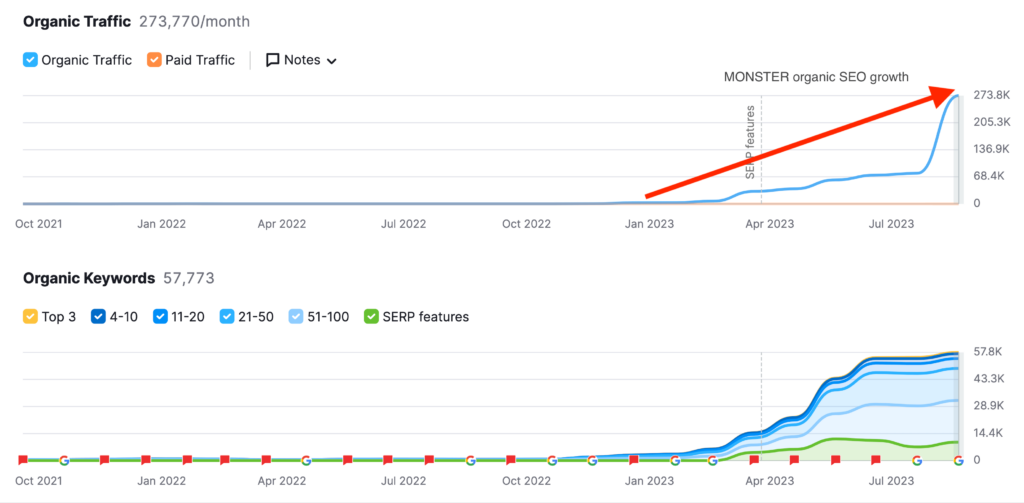
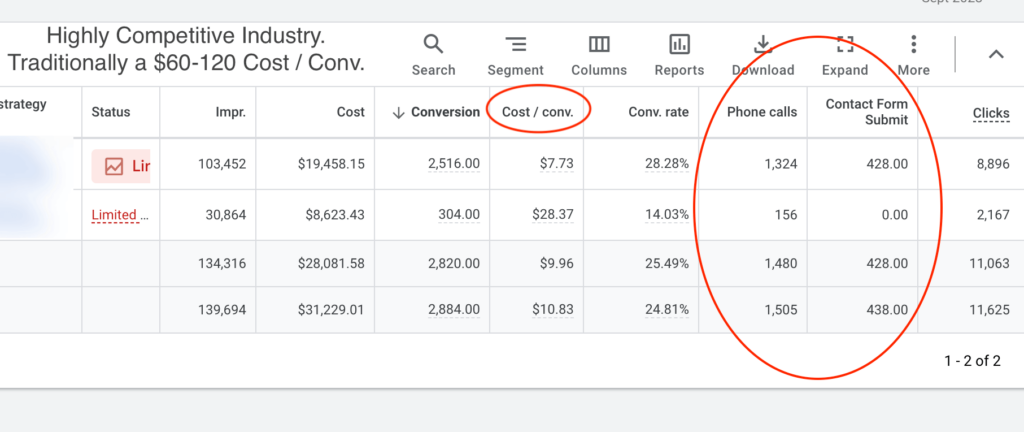
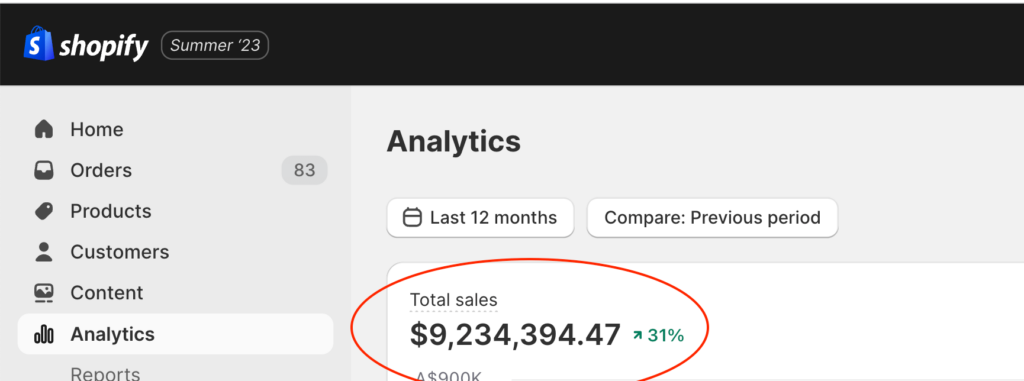
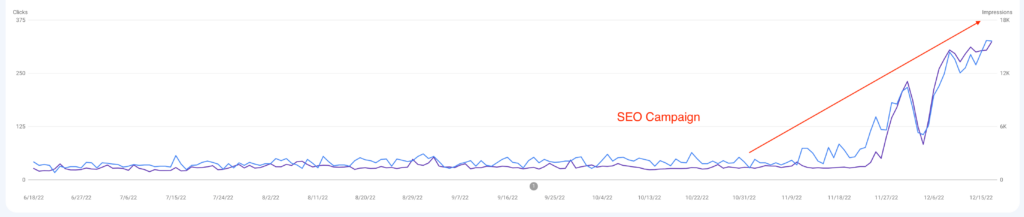
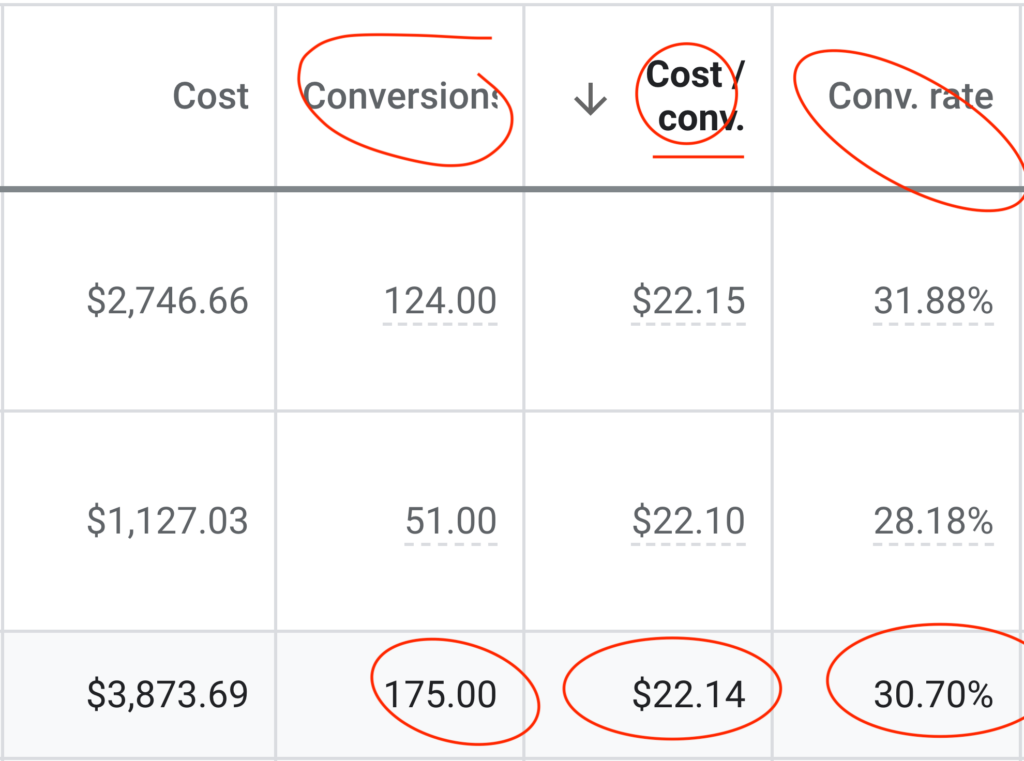
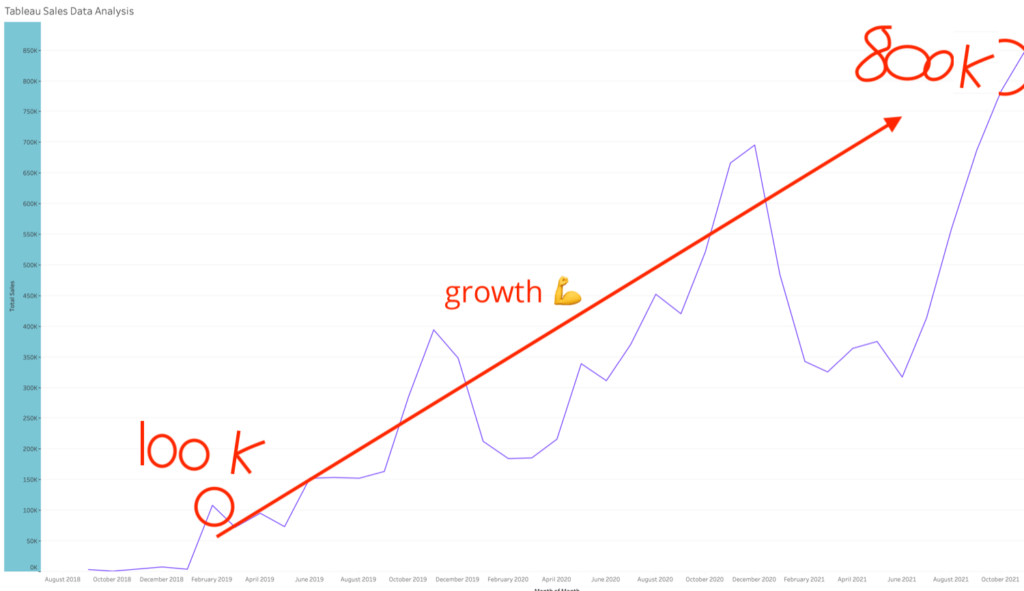

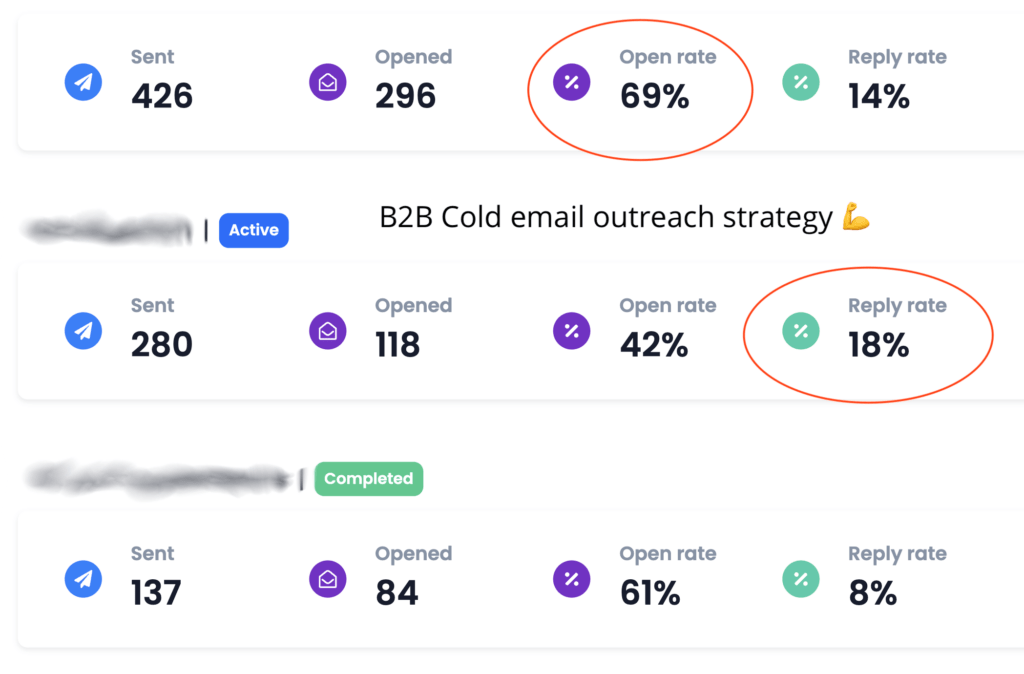
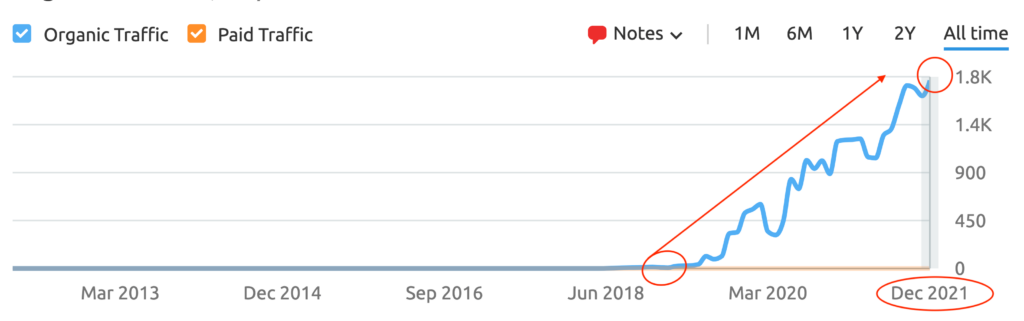



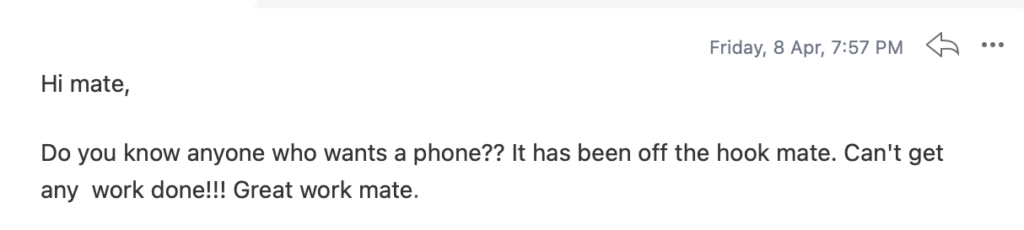

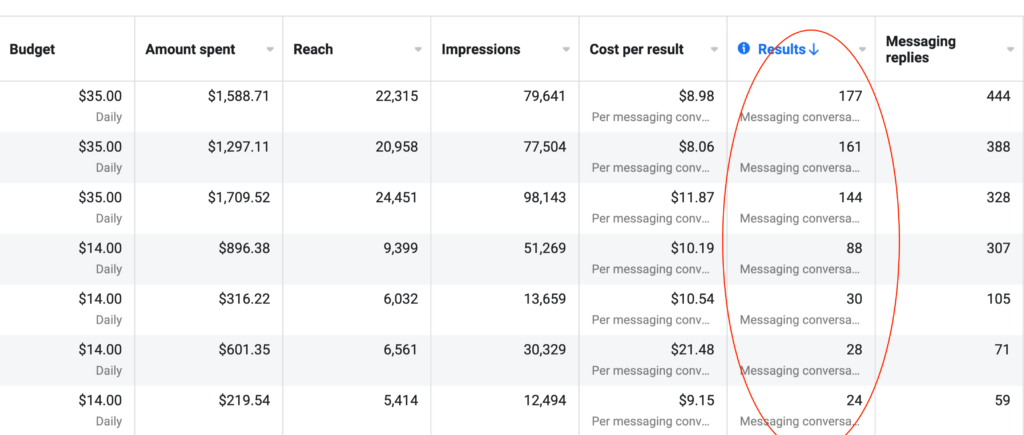
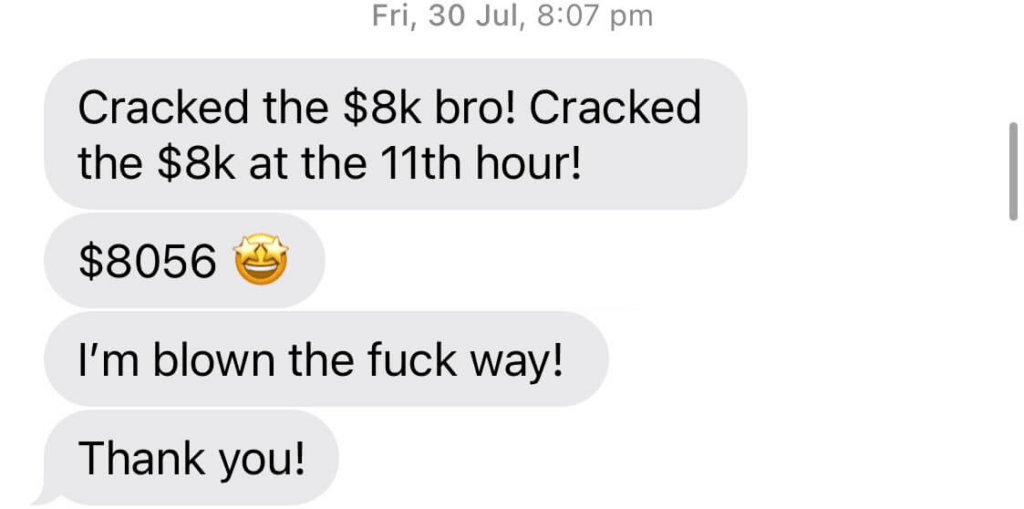

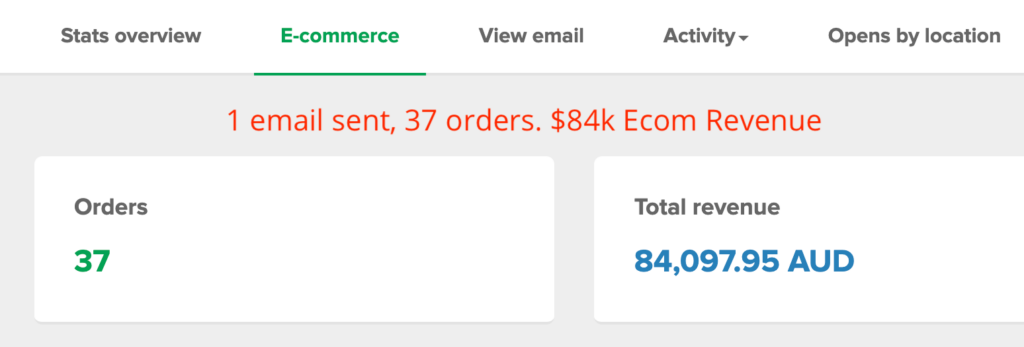
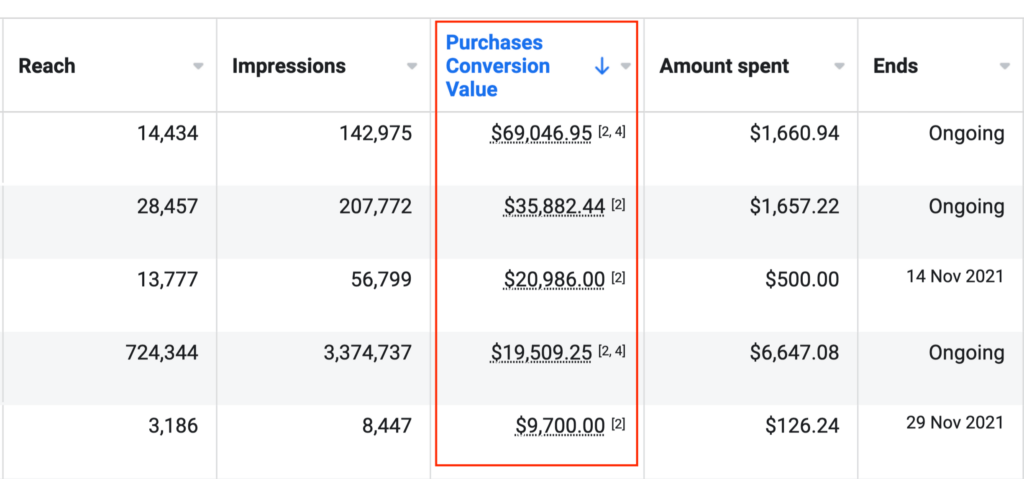
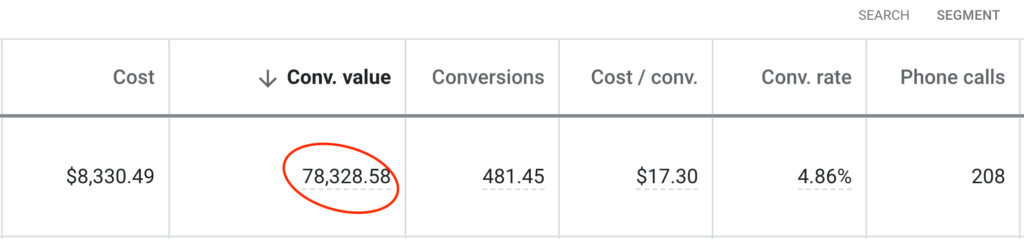
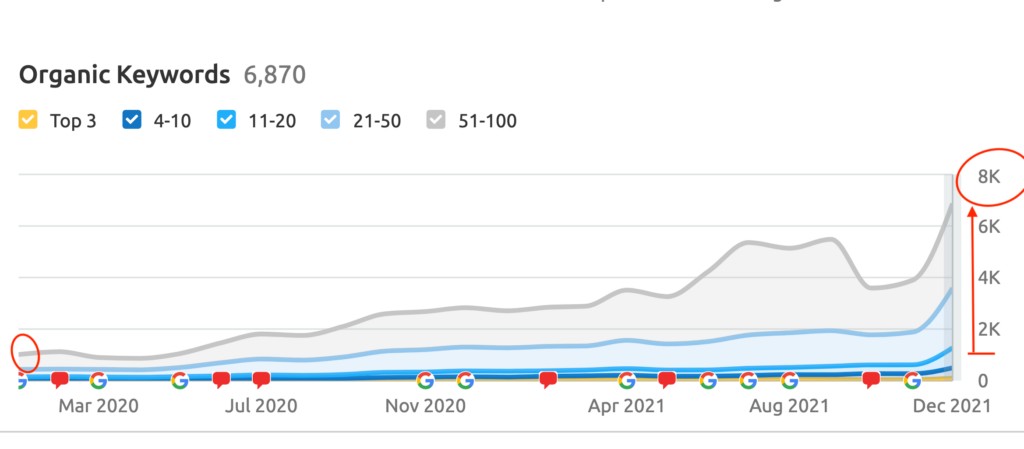
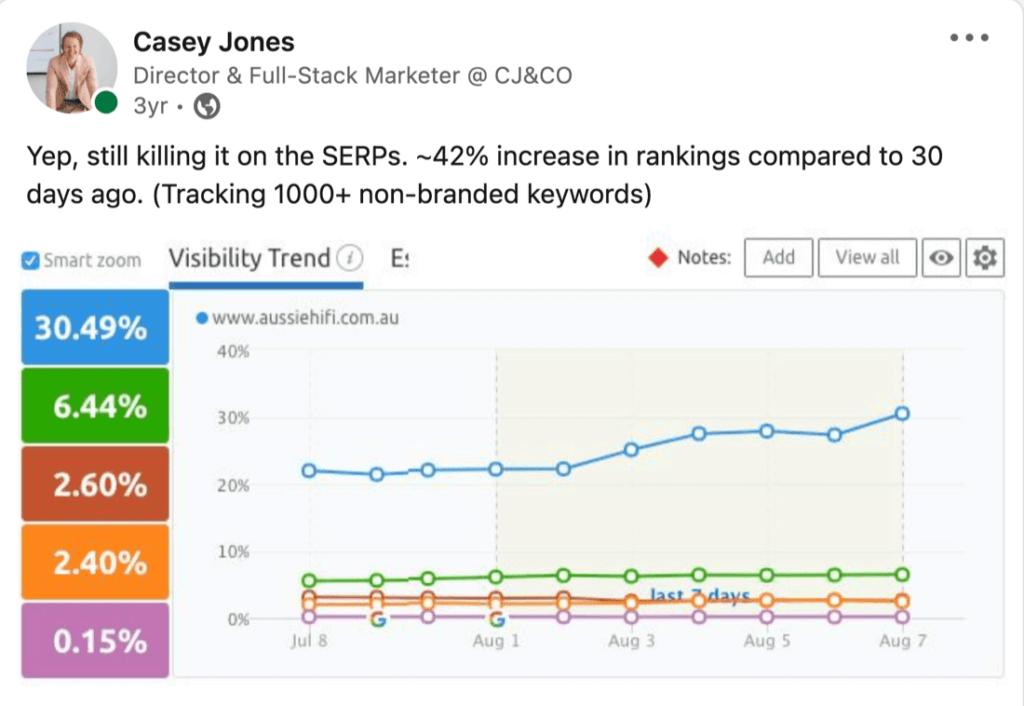

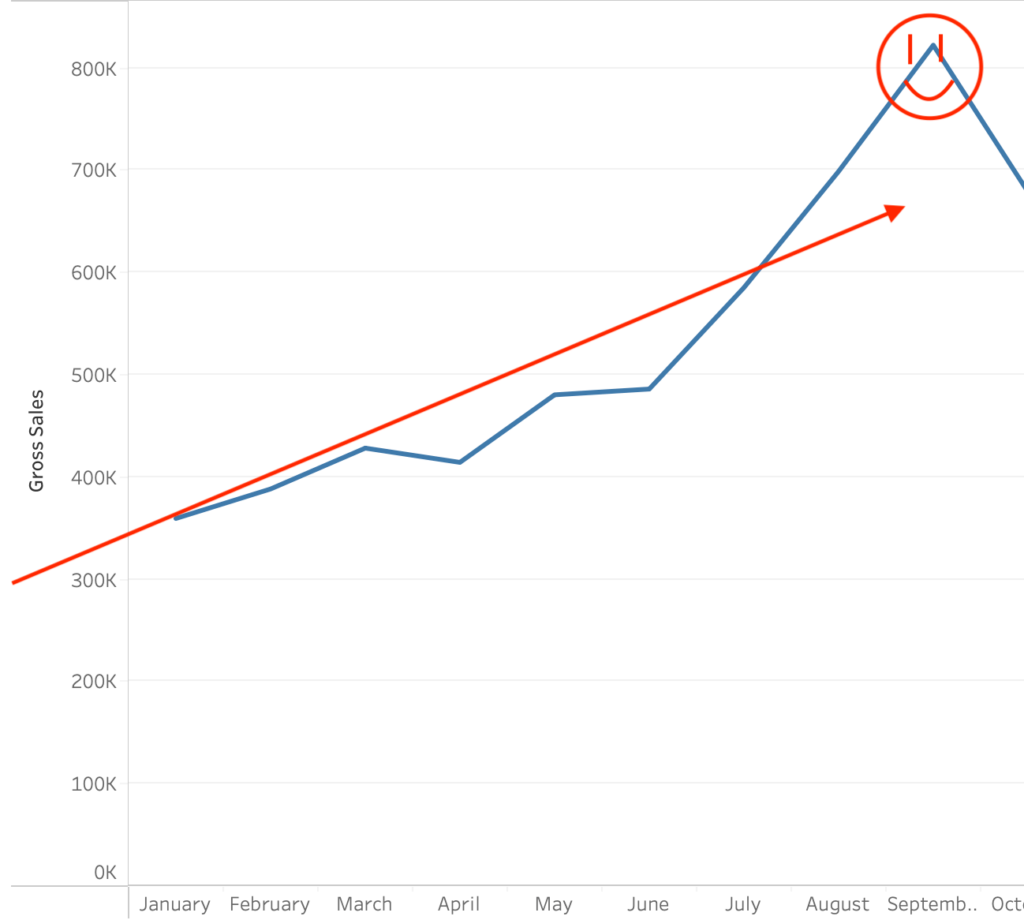
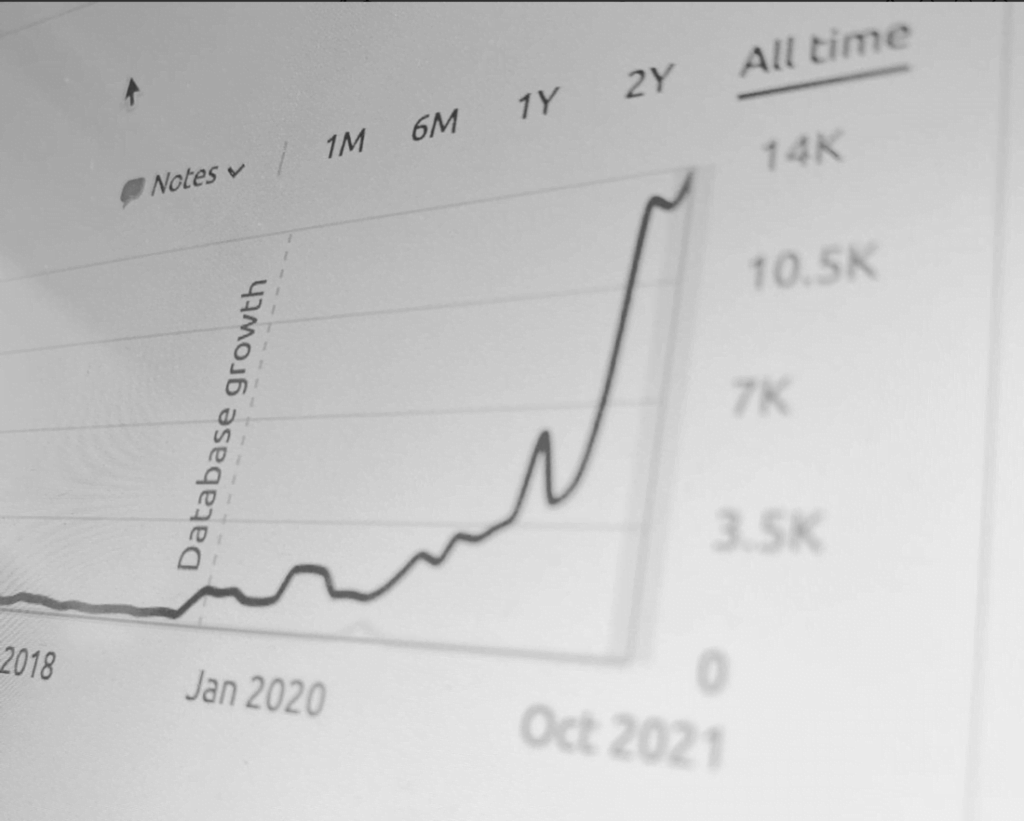

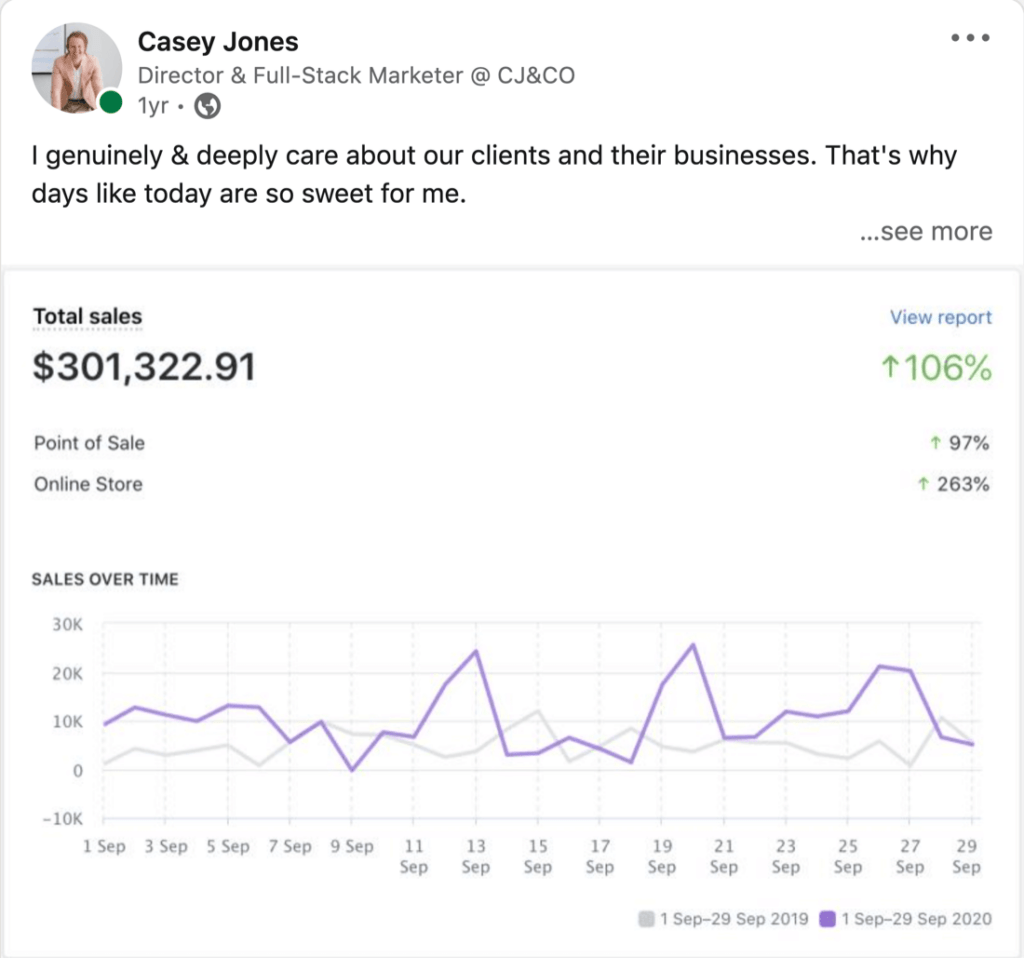

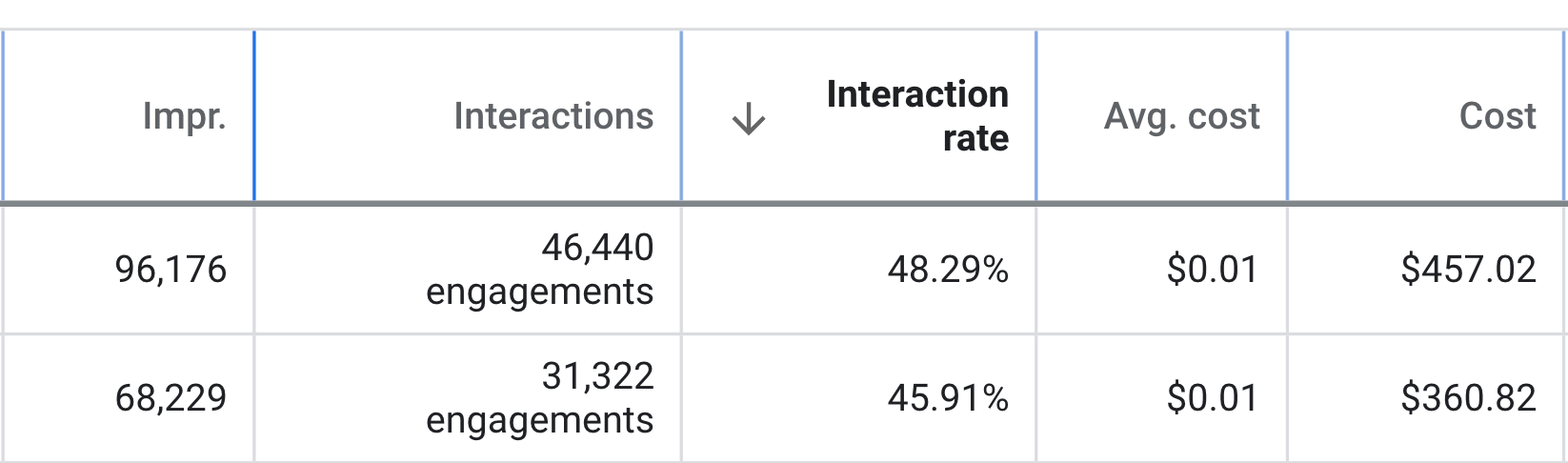
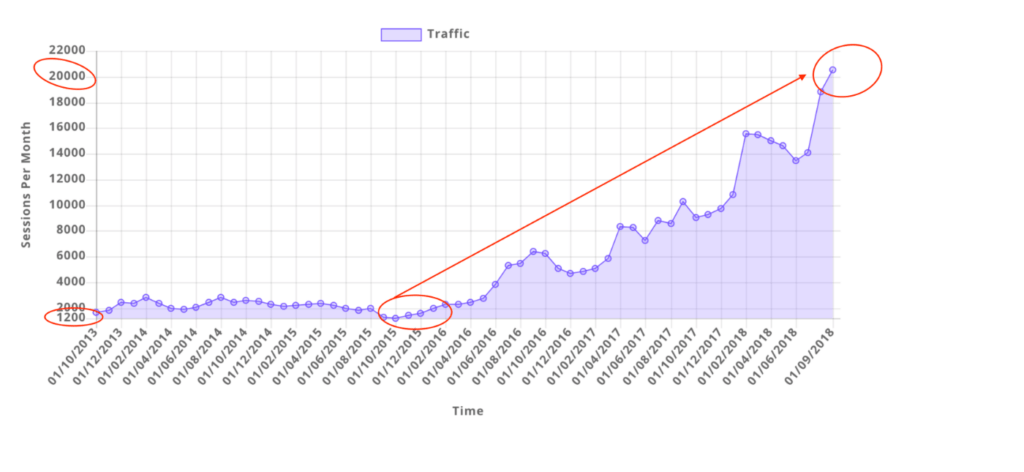
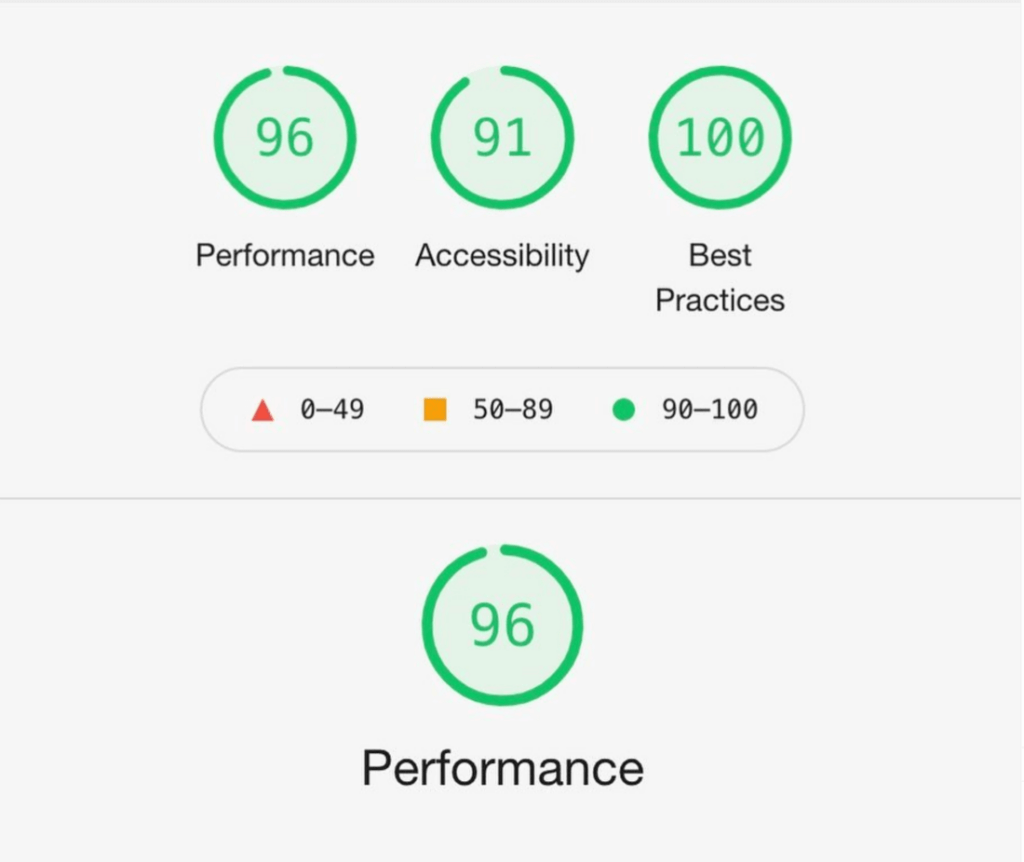
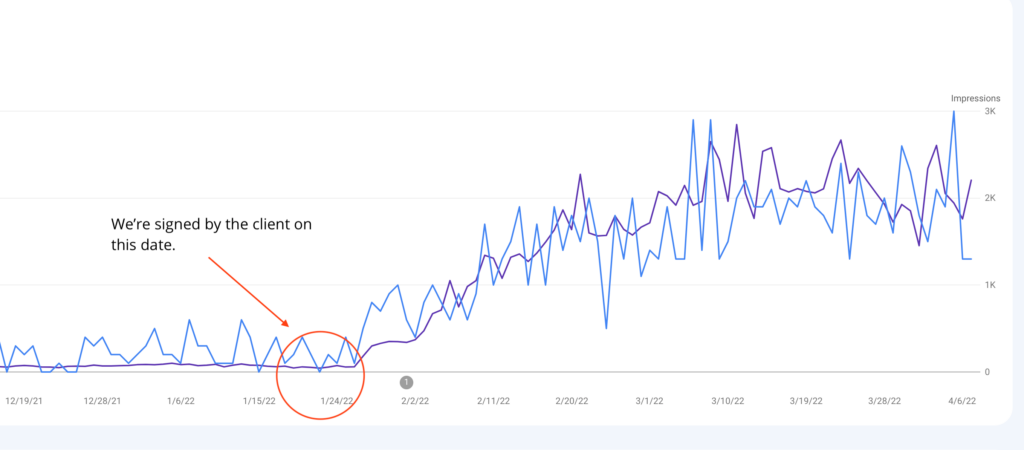
























To the insightful marketing behemoth that Casey brings to our whole world of getting in the customers focus zone, once again your insightful strategies always go above and beyond the normality of blanket marketing and get us some enviable results from our competitors and partners alike. Keep up the efforts mate. You are our connection to the customer.Read moreRead less
Up until working with Casey, we had only had poor to mediocre experiences outsourcing work to agencies. Casey & the team atm at CJ&CO are the exception to the rule.
Communication was beyond great, his understanding of our vision was phenomenal, and instead of needing babysitting like the other agencies we worked with, he was not only completely dependable but also gave us sound suggestions on how to get better results, at the risk of us not needing him for the initial job we requested (absolute gem).
This has truly been the first time we worked with someone outside of our business that quickly grasped our vision, and that I could completely forget about and would still deliver above expectations.
I honestly can't wait to work in many more projects together!Read moreRead less
Casey has gone above and beyond, he has delivered our standing results and through out the whole time from bouncing ideas around to the final result he has been super heap full and outstanding with his communication. I am so keen to post this video and share around, once again thank you Casey!!!Read moreRead less
Casey is professional, enthusiastic and knowledgeable. He was quick to identify where we could improve our business, and made a huge impact to our brand.
Could not recommend these guys enough!Read moreRead less
Extremely happy with Casey and his team. If you're looking for a highly experienced, knowledgeable and ideas-driven marketing agency, look no further. Not only is Casey exceptionally skilled at creating highly effective marketing strategies and delivering real results, he's a pleasure to work with and a great communicator. He's helped transform our business from a fairly humble start-up to a fast growing and highly regarded service provider in our industry. He knows his stuff and we couldn't be happier. Five Stars.Read moreRead less
The enquiries just keep coming and the business is now unrecognisable. But, what we like most about Casey, is he's a great communicator, really easy to work with and responsive to our needs.Read moreRead less
FIT Merchandising have been using the CJ & Co for about 7 years and love the professionalism , timely turnaround on projectsects , cost structure and all round quality of service we receive form them. Casey is highly skilled in all things digital marketing our brand would be lost with out his and his team.Read moreRead less
CJ&CO has helped me to steadily gain clients so much that I'm now looking at taking on additional staff to meet the the demand.Read moreRead less
I'd highly recommend Casey to business owners who are looking to take that plunge to market their business online.
Within a very short amount of time, the leads coming in the door were AMAZING!
My business is thriving. They developed a new easy to use website for me whilst also managing my Google AdWords account.
I used to enjoy doing my own marketing. Landing leads and cinching clients is a real endorphin rush. However, it was very hit or miss. One day, something changed and after almost $300 in Facebook ad spend, I didn’t land a single lead. I couldn’t figure it out and got referred to CJ&CO from a fellow OT. Within a month, with Casey's short-term strategy, the leads were rolling in!Read moreRead less